|
|
 发表于 2018-4-20 13:15:33
|
显示全部楼层
发表于 2018-4-20 13:15:33
|
显示全部楼层
本帖最后由 eqblog 于 2018-4-20 13:24 编辑
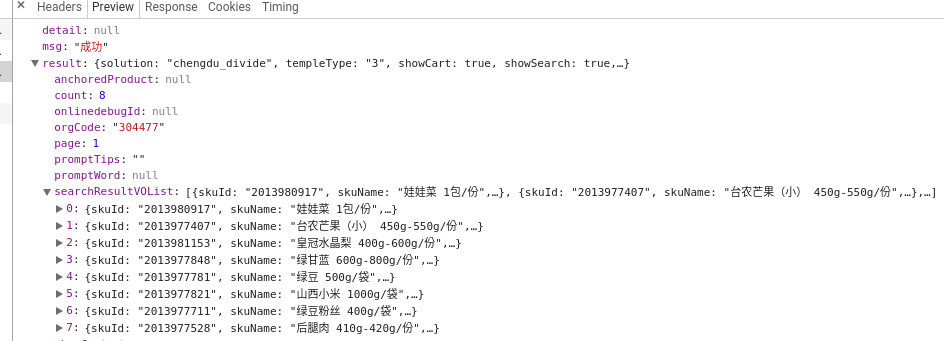
 我建议你直接解析js爬 我建议你直接解析js爬
 后面还有就得你自己解析规则了。。 后面还有就得你自己解析规则了。。
算了我还是说完整点吧,
_djrandom=15242011656893&functionId=productsearch%2Fsearch&body=%7B%22key%22%3A%22%22%2C%22catId%22%3A%22%22%2C%22storeId%22%3A%2211679831%22%2C%22sortType%22%3A1%2C%22page%22%3A1%2C%22pageSize%22%3A10%2C%22cartUuid%22%3A%22%22%2C%22promotLable%22%3A%223%22%2C%22timeTag%22%3A1524201165372%7D&appVersion=5.2.0&appName=paidaojia&platCode=H5&jdDevice=&signKey=bf2f52936dc8b91fc37230f6d5d40dc0&jda=122270672.534238949.1521674021.1521776846.1523854618.4
然后解码下你就可以看到 有个 body:{"key":"","catId":"","storeId":"11679831","sortType":1,"page":1,"pageSize":10,"cartUuid":"","promotLable":"3","timeTag":1524201165372}
修改这里的值就能获取每个分类 页数的数据 |
|



 刚刚说错了 见谅
刚刚说错了 见谅 楼主
楼主